Handling categorical variables
- staniszradek
- 1 lip 2024
- 3 minut(y) czytania
#Pandas #categorical data #Encoding #scikit-learn
There are two main types of data; quantitative and qualitative (categorical). Quantitative variables represent amounts that can be added, subtracted, divided ,etc. Categorical variables are some kind of groupings that can take on one of a fixed, number of possible values. Oftentimes we need to convert categorical data in order to use it in our models. Today I am going to look at some popular methods to do so.
Before converting our variables, let's quickly recall how can we check the types of our variables. We can use for example dtypes method which gives us an overview of all columns and their types. Once we identified our categorical variables, we can use unique() function to check how many distinct values (categories) a particular column has. This is very useful function as we can also quickly identify whether there are any typos and/or duplicated categories that should be cleaned.
df['Category'].unique()
Categorical variables can be broken down into further types: binary (yes/no), nominal (groups with no order) and ordinal (groups with order between them). Depending on the type of categorical variable we use slightly different methods to convert it. Let's come up with some simple example:
categories = ['book', 'e-book', 'audiobook']
levels = ['easy', 'intermediate', 'hard']
category_data = np.random.choice(categories, 15)
level_data = np.random.choice(levels, 15)
df = pd.DataFrame({
'Category': category_data,
'Level': level_data
}) As we can see there are 2 categorical variables : 'categories' and 'levels'. Obviously there's a natural order among values of 'levels' variable what makes it an ordinal variable. The other one is nominal as there's no order between 'book', 'e-book' and 'audiobook'. So, how do we change these values into numbers? Let's start with ordinal variables. As mentioned above, we need to give our categories some kind of logical order. This will not be possible if we stick to the default 'object' type of the `Level' column. We need to transform this variable into 'category' dtype. This can be achieved by employing astype() function. Only then we are able to specify an order among categories and encode them with corresponding numbers.
df_enc['Level_enc'] = (
df_enc['Level'].astype('category')
.cat.set_categories(['easy', 'intermediate', 'hard'])
.cat.codes)Let's see the output of the code above:

It looks like we converted and encoded the categories correctly according to the logical order. There are also other benefits of using 'category' dtype in Pandas which are listed and explained in the documentation.
In case of nominal variables pandas offers get_dummies() method (One-Hot Encoding). What it does is basically creating new boolean columns that represent each category of our original column. It works well if there is a reasonable number of categories. Otherwise we end up with a lot of new features which may sometimes be a problem. The number of unique categories is called `cardinality`. So if we deal with a high - cardinality column, it may be reasonable to try different approaches in order to keep the dataset relatively small.
df_enc = pd.get_dummies(df_enc, drop_first=False, dtype=int, columns=['Category'])There are some parameters to be set in get_dummies() in order to achieve exactly what we want. In this case I specified the type of new clolumns (by default it returns True/False, also I specified which column I want to dummy encode and decided to keep all categories (it may be beneficial to drop one category resulting in n-1 dummies out of n categories). All parameters are explained here.
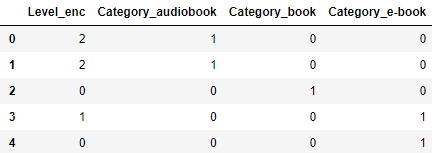
Now our both categorical variables are represented by numbers and can be used in many machine learning models.
The same results can be achieved by using OrdinalEncoder and OneHotEncoder respectively from scikit-learn library. First we need to import both functions:
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import OrdinalEncoderThen we instantiate OneHotEncoder, fit it and transform the data into one-hot format. The next step is to create a dataframe with transformed data and get the names of the columns using 'get_feature_names_out' method.
encoder = OneHotEncoder(sparse_output=False, dtype=int)
one_hot_encoded = encoder.fit_transform(df[['Category']])
one_hot_df = pd.DataFrame(one_hot_encoded, columns=encoder.get_feature_names_out(['Category']))output:

And in case of ordinal features:
ordinal_encoder = OrdinalEncoder(categories=[['easy', 'intermediate', 'hard']], dtype=int)
ordinal_encoded = ordinal_encoder.fit_transform(df[['Level']])
ordinal_encoded_df = pd.DataFrame(ordinal_encoded, columns=['Level_encoded'])
df = df.join(ordinal_encoded_df)output:
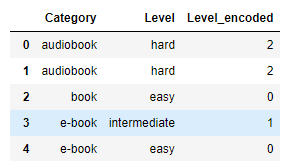
More on encoding categorical features in scikit-learn library can be read here.
Comments